This project involves extracting narrative timelines from natural language text, i.e., understanding the order and timing of events mentioned in a narrative, in order to enable automatic reasoning over this information.
A new kind of question-answering dataset that combines commonsense, text-based, and unanswerable questions, balanced for different genres and reasoning types. Reasoning type annotation for 9 types of reasoning: temporal, causality, factoid, coreference, character properties, their belief states, subsequent entity states, event durations, and unanswerable. Genres: CC license fiction, Voice of America news, blogs, user stories from Quora 800 texts, 18 questions for each (~14K questions).
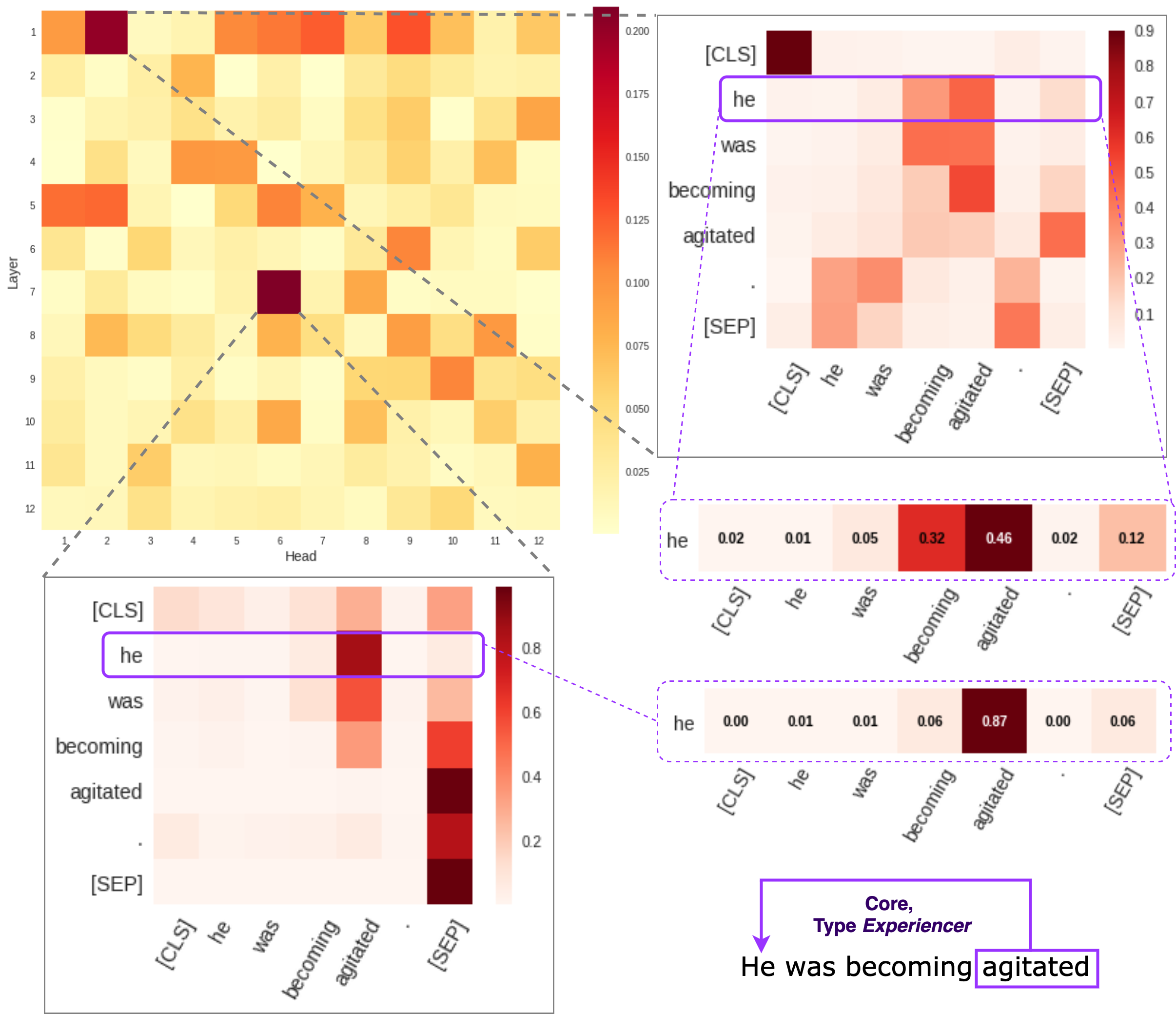
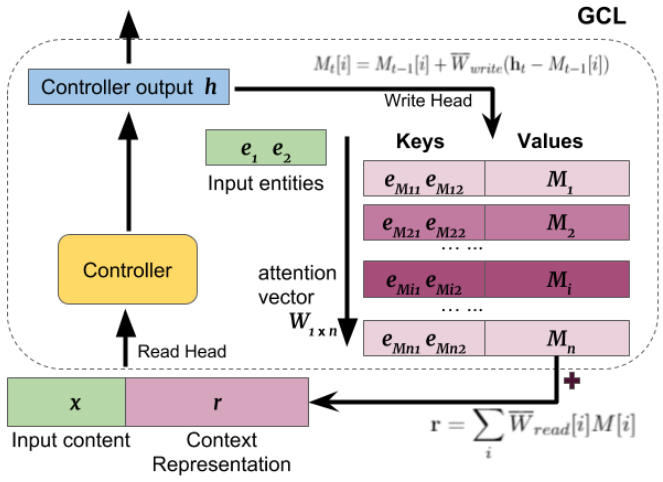
With the advent of large language models, a little is known about the exact mechanism which contributes to the model success. In this project, we developed different analyses methods (e.g. attention pattern analysis) to understand how information is represented in large language models.
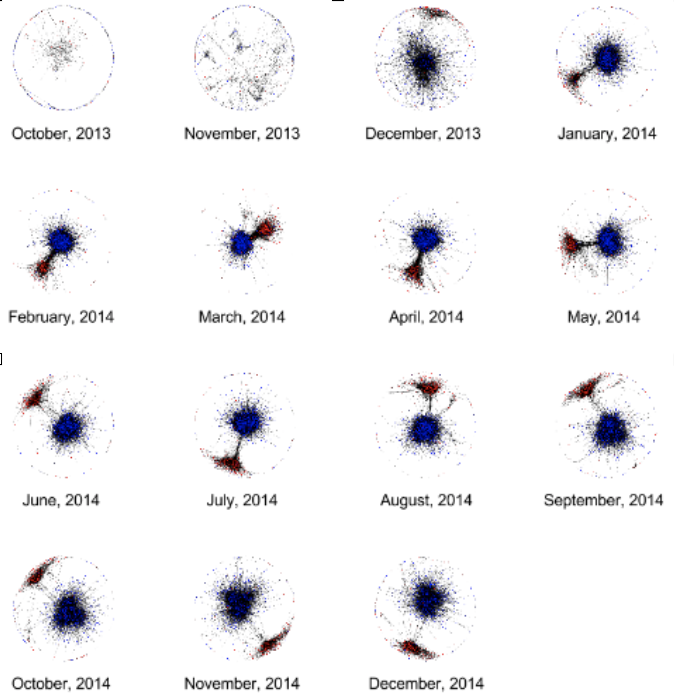
This project develops methods for modeling, detecting and measuring civil conflict as reflected in social media, as well as the associated informational biases in the news media. The goal is to combine different measures of verbal and non-verbal user behavior and the associated network-scale effects in order to track conflict development over time.
We view the problems of conflict and bias detection as inherently intertwined, since conflicts often lead to biased interpretations on both sides. The goal is to evaluate the hypothesis that identifying user communities divided with respect to a set of polarizing issues will allow us to characterize relevant information sources in terms of ideological biases propagated by the opposing sides.
In this project, we investigated several approaches to argument mining, including (a) using Pointer Networks to identify links between argument constituents, (b) studying memory networks and other methods for knowledge integration in service of argument mining, and (c) integrating external signal in order to predict winners in Oxford-style debates.
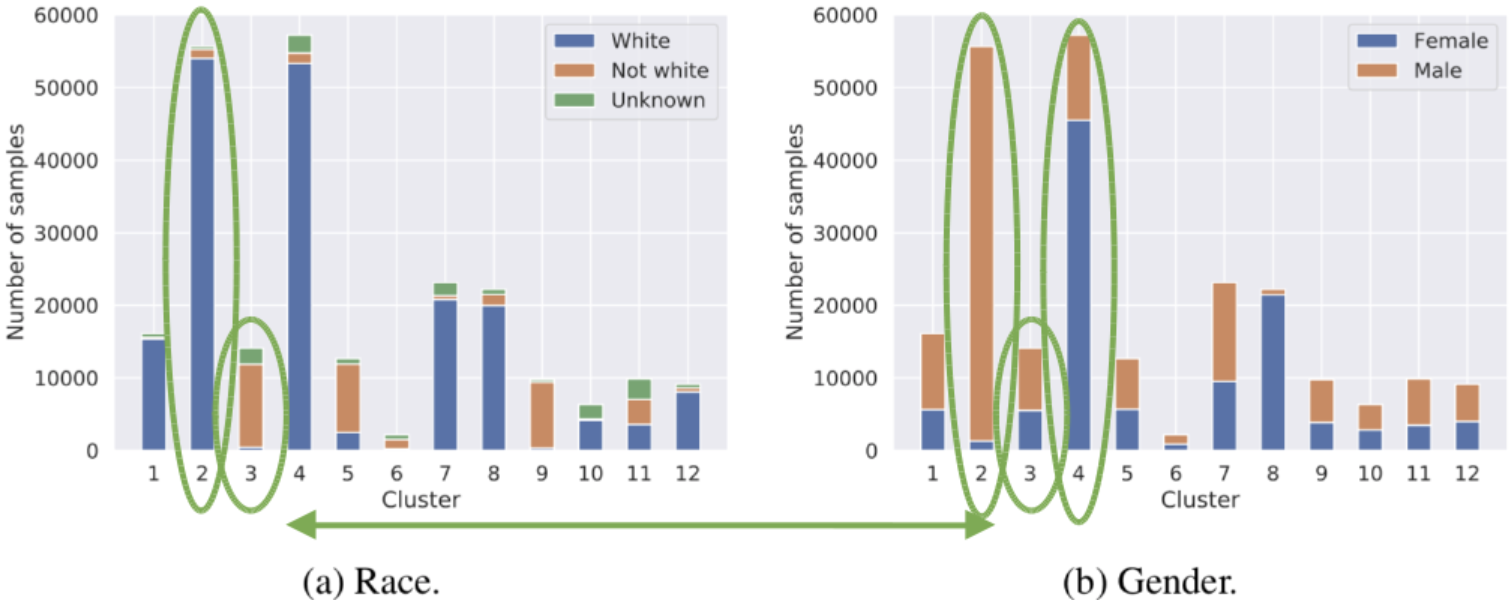
The idea behind this project was to use human names as a proxy for protected attributes (gender, age, ethnicity, race, etc.) Classification loss is supplemented with the loss minimizing correspondence between name clusters and predictions (specifically, occupation and income).
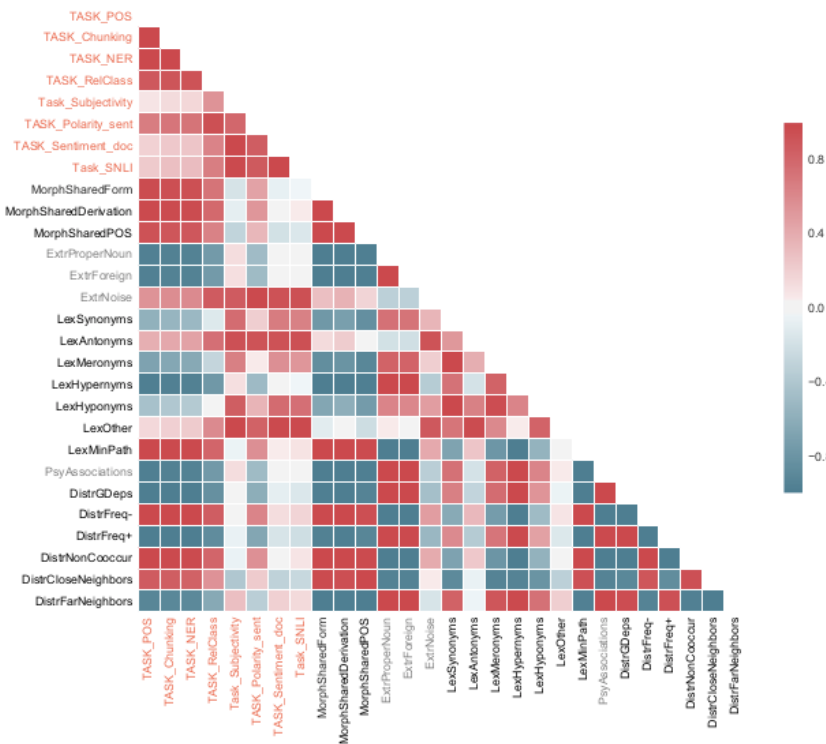
Word embeddings are the most widely used kind of distributional meaning representations in both industrial and academic NLP systems, and they can make dramatic difference in the performance of the system. However, the absence of a reliable intrinsic evaluation metric makes it hard to choose between dozens of models and their parameters. This work presents Linguistic Diagnostics (LD), a new methodology for evaluation, error analysis and development of word embedding models that is implemented in an open-source Python library. In a large-scale experiment with 14 datasets LD successfully highlights the differences in the output of GloVe and word2vec algorithms that correlate with their performance on different NLP tasks.

RuSentiment is a new high-quality dataset for sentiment analysis in Russian, enriched with active learning. We also present a lightweight annotation scheme for social media that ensures high speed and consistency, and can be applied to other languages (Russian and English versions released).
The Knowledge Evolution project is an experiment in tracking and mapping the evolution of knowledge domains as well as the reputations and intellectual networks of the past. The project uses the history of the Library of Congress book acquisitions and classification, and the text of historical and contemporary editions of Encyclopedia Britannica and Wikipedia.
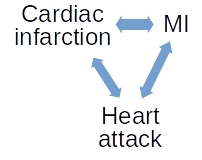
This project addresses the problem of normalization of medical records, i.e. mapping of clinical terms in medical notes to standardized medical vocabularies.
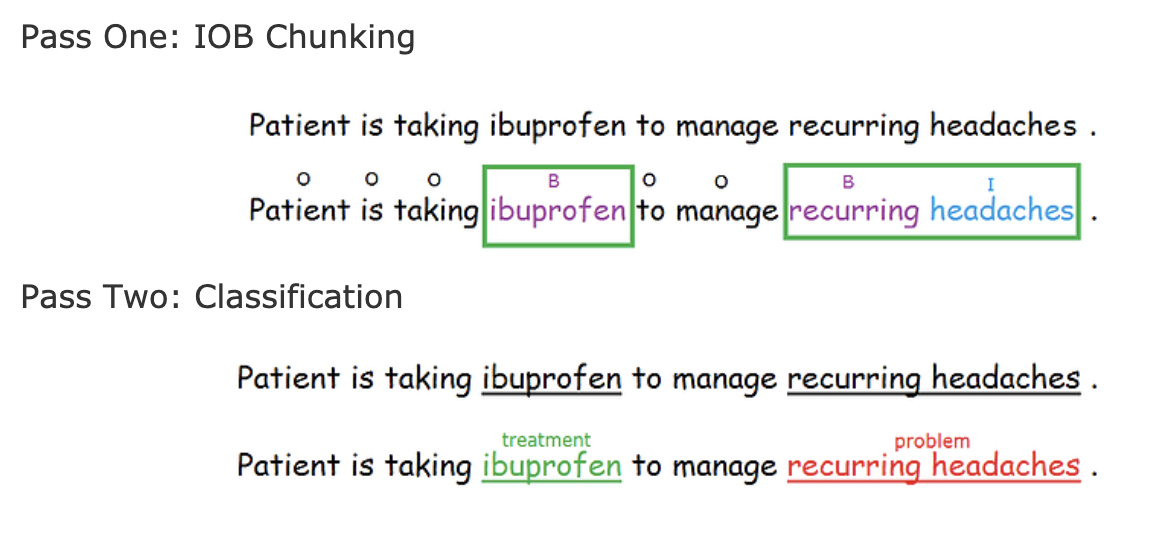
Clinical Named Entity Recognition system (CliNER) is an open-source natural language processing system for named entity recognition in clinical text of electronic health records. It supports:
- a traditional machine learning architecture for named entity recognition with a CRF classifier
- a deep learning architecture using a recurrent neural network with LSTM for sequence labelling
TwitterHawk is an open-source natural language processing system for Twitter sentiment analysis. This system was developed for the SemEval-2015 Task 10: Sentiment Analysis in Twitter.
We were involved in the development of CPA (Corpus Pattern Analysis), a technique for mapping meaning onto words in text that is based on the Theory of Norms and Exploitations. In CPA, meanings are associated with prototypical sentence contexts, which makes it a promising approach for automatic word sense disambiguation.