System Architecture
- Extensible, easy-to-use architecture
- Implemented in Python, using sklearn, CRFsuite, and LibSVM
- Support for multiple formats, currently supporting:
- word offset-based format
- inline XML
- character offset-based format
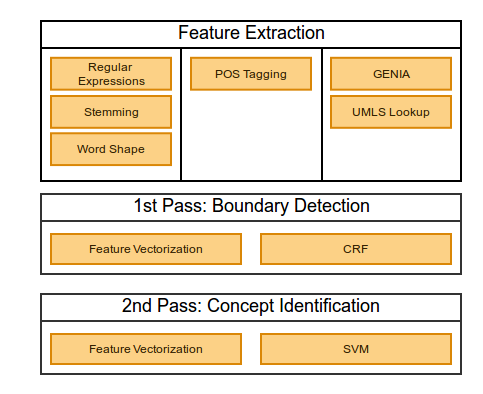
Two-Pass Machine Learning
Pass One: IOB Chunking

Pass Two: Classification

Features
- Concept boundary detection
- General text features:
previous 3 unigrams, next 3 unigrams, current word's POS, unigram w/digits replaced by #, other word shape features, previous two tokens' features, following two tokens' features - Genia features: GENIA stem, GENIA POS, GENIA chunk-tag
- UMLS features: UMLS CUI, UMLS semantic type
- Prose and non-prose contexts processed separately
- General text features:
- Concept Type Identification
- Additional features: regular expressions for dates, test results, doctor abbreviations
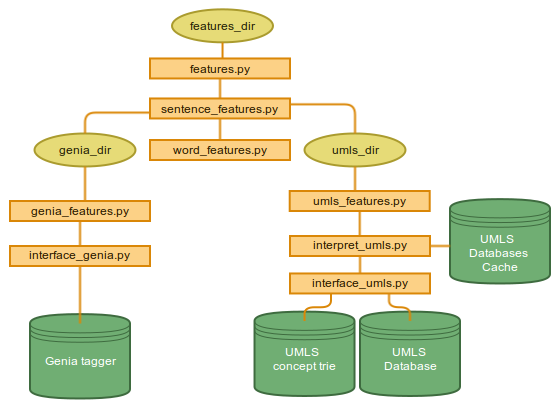
Features Directory
CliNER is designed to run out-of-the-box and be as lightweight as possible. However, there are also options for enabling additional features in order to achieve better prediction results. By changing the config file located at $CLICON_DIR/config.txt, you can enable modules that extract additional Machine Learning features using the GENIA tagger and UMLS databases. See the README for info about how to obtain these modules. Here is the organization for how features are extracted from given input text.
System Components
Basic system functionality
- train.py, predict.py, evaluate.py
Utilities
- command-line interface, installation & config tools, etc.
- helper.py, is_installed.py, cli.py, format.py, read_config.py
Data representation
- pipeline logic, storage for the two-pass implementation, etc.
- note.py, model.py
Features
- features.py, sentence_features.py, word_features.py
- genia: genia_features.py, interface_genia.py
- umls: umls_features.py, umls.py
Machine Learning: ML library wrappers
- sci.py, crf.py
Extensible Reader/Writer for Data Formats
Adding your reader/writer is done by adding a file in the $CLICON_DIR/clicon/notes. The file should be named note_%s.py (where %s is the name of your format). Inside this file, you must define an object named Note_%s (where %s is again your format name). This class must inherit from the AbstractNote object. Now all that remains is defining the abstract methods inherited from the base class and you will be able to read any formats you need.
All format specifications (be it through CLI, python scripts, etc) all check the ''notes'' directory to determine what formats the system can read.